IMAP Monitoring Enhancements
2013/01/09 Leave a comment
On the heels of our SMTP enhancement release, we’re happy to add some significant features to our IMAP server monitoring check. IMAP refers to one of the two most popular methods of email retrieval, the other being POP. IMAP4 services are supported by nearly all email clients and its use continues to grow.
We’ve added the following enhancements:
- Non-standard ports. Specify any port, not just IMAP default port 143
- SSL/TLS support.
- SSL certificate validation
- SSL certificate expiration warnings – configurable to X days before expiration
- User login verification.
It’s easier than ever to ensure your IMAP services are available and configured correctly. Find more information about the new enhancements in our documentation.
The new IMAP enhancements are available to all NodePing accounts today. If you don’t have a NodePing server monitoring account yet you can sign up for a free 15-day trial.
Next check on the block for more enhancements – you guessed it – POP3. I hear there’s a RBL check in the works too! Keep an eye out here on the blog for the announcements.
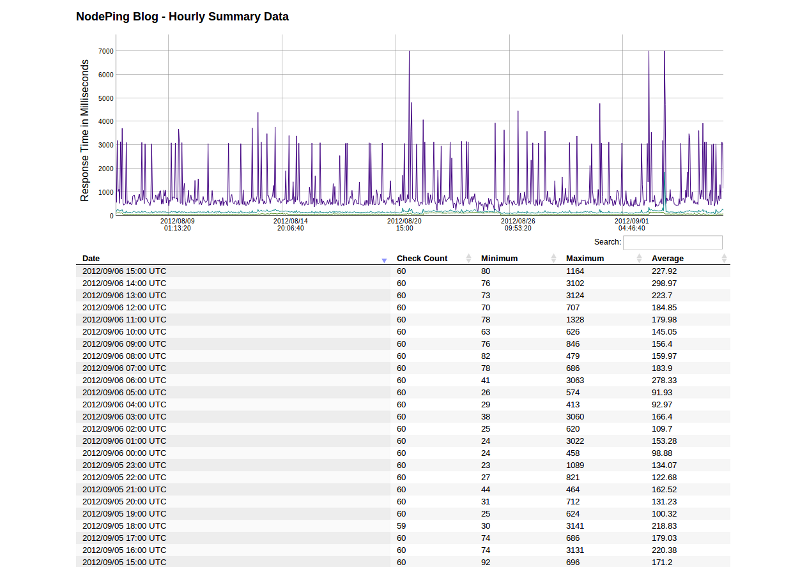 We have implemented a new report to help with this task. The Performance Summary report shows the minimum, maximum, and average response time for a site over an hour. By default, the report shows the last 31 days of performance data. As with the results report, you can change the number of results shown by editing the number on the report’s URL.
We have implemented a new report to help with this task. The Performance Summary report shows the minimum, maximum, and average response time for a site over an hour. By default, the report shows the last 31 days of performance data. As with the results report, you can change the number of results shown by editing the number on the report’s URL. 
