Recently, Let’s Encrypt announced they will be ending support for expiration notification emails by June 4, 2025. With this upcoming change, many are looking to alternate ways to monitor certificate expiration dates. At NodePing, we offer the capability to monitor your SSL certificates with our SSL check. Our SSL check lets you monitor certificate validity as well as notify you when your certificate is about to expire, that way you can make sure your certificate renewals are happening as you would expect, and fix it when it’s not.
Using the SSL Check
Our SSL check isn’t just limited to monitoring port 443 on your web server. You can also monitor non-website TLS services by using the URL port convention. For example, setting the target to “https://example.com:8000”. The check can be used to monitor SSL certs on services such as DoH, MQTT, Websockets, email, anything that accepts a TLS connection.
The most popular use for the SSL check is to monitor for an expiration date and alert the user at a defined number of days before expiration. However, the SSL check is also useful for diagnosing certificate chain errors. This can be useful to diagnose missing intermediary certificates or mismatched certificates in the SSL chain, for example.
If you don’t have a NodePing account yet, give it a try! We offer a free, no-obligation 15-day trial. The best way to see if NodePing meets your needs is to try it out.
In today’s world, VPNs have become more popular and widely used. Some common use cases have been road warrior VPNs when you are on the go, site-to-site VPNs for satellite offices, and remote connections back to the office for those who work from home (WFH). Since VPNs have become so central to many of our activities, it is important to ensure that the VPN setup you are using is both available and working as intended. This sort of monitoring is readily available with our AGENT feature.
The NodePing AGENT is designed to run NodePing monitors on your own private infrastructure. The AGENT allows you to run checks you want from any network, as long as you can stand up a Linux computer to run the AGENT. This includes locations we do not have a public probe, like your local networks, and even over VPN connections. Once you have an AGENT created and running, you can assign checks to the AGENT as the location, and the checks will run on the AGENT automatically. Most of our check types are available to use to monitor services and connectivity, which allows you to monitor your VPN resources without having to allow our public probes into your network. No firewall changes needed!
The AGENT can work with many different VPN setups. For example, configuring your AGENT computer or VM to be a WireGuard peer to monitor a WireGuard VPN. This works with other VPNs as well, such as monitoring OpenVPN connections or you can monitor IPSec or IKEv2 VPNs. With connectivity to your remote network, you can run your checks to ping internal servers, do local DNS queries, which can be useful if you have a split-DNS configuration, or HTTP connections to your local servers, and it can test outbound connectivity to the Internet.
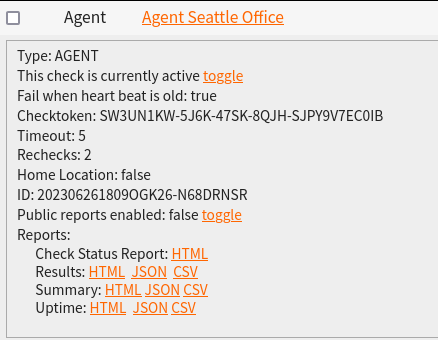
To get started running the AGENT, you need to first create an AGENT check on NodePing. This can be done either by signing into your account on our website, or via the API. You can find this information in our documentation. The AGENT check creates the AGENT instance so you can assign checks to it. The AGENT software also sends a heartbeat so you can ensure the AGENT is running and doing its jobs. To create the AGENT check, follow these steps:
Click “Add new check”
Select AGENT from the Check type drop down
Label the AGENT to identify it, adding a meaningful location to the label. This label is what will appear in the locations list when you assign checks to run on the AGENT
Set the Check Frequency. 1 minute is recommended
Optionally set “Fail when heartbeat is old” so you can know if the Agent is not submitting results
Set notifications for the check
Then save the check
Next, to run the AGENT software on your computer, install NodeJS on your Linux distribution of choice, then you can proceed with installing the AGENT. The instructions can always be found on our GitHub repository, but for now, here’s the short version as an example:
The Check ID and Checktoken in the example above are used to tie this instance of the AGENT running on your computer to the check running on NodePing. They can be found with the check information on the NodePing site:
The install command will set up the AGENT to run, and at this point you can now create checks to be assigned to this AGENT. To do that, create a check, and in the “Region” dropdown, select the name of the AGENT you just created. After creation, you should begin to see the checks running on your AGENT.
Additionally, if you want to take advantage of our Automated Diagnostics or our other Diagnostic Tools, you can start the Diagnostic Client on your computer as well:
Now that you have the AGENT software running on your computer, and the AGENT check set up and connected, we can start assigning checks to run on this AGENT. In this scenario, let us assume we have an internal web server at 192.168.20.150, an internal DNS server we want to query at 192.168.20.100 and make sure it is returning 192.168.20.150 for our internal webserver FQDN internal.example.com, and lastly test to see that we can ping something on the Internet too so we know our clients can connect to the Internet through the VPN.
For the Web server, let’s set up an HTTP check to run on the AGENT
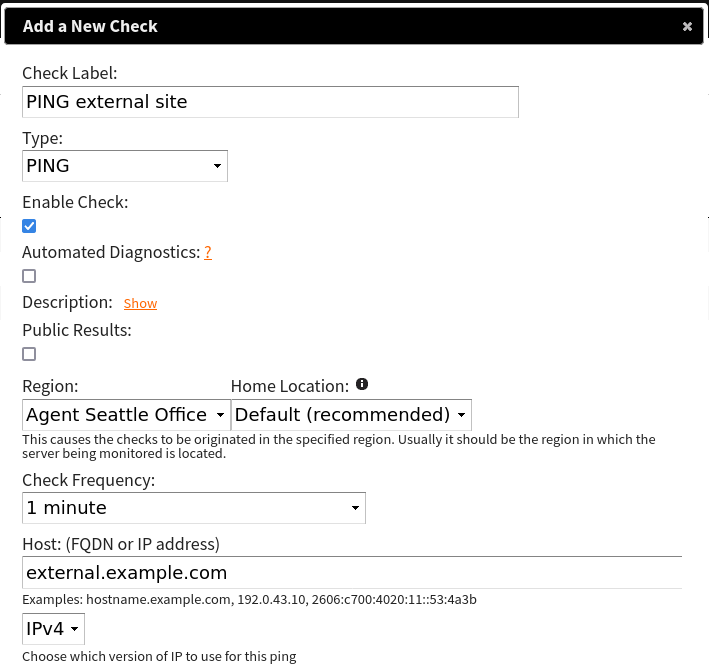
Note the “Region” dropdown and that I selected the AGENT I created earlier.
Next we want to make sure that we are getting the proper internal IP address for that web server:
Here, we configure the check to make a query to the internal DNS server 192.168.20.100 and expecting the answer 192.168.20.150 for internal.example.com.
Lastly, we want to ping an external server to see that clients can reach the Internet. This is useful if you do want your VPN clients going out to the Internet too. For this example, we would ping external.example.com (note these aren’t real websites):
This is all only one example of many ways you could configure your VPN monitoring. Our AGENT is capable of handling all sorts of different monitoring tasks you may want to throw at it.
The NodePing AGENT is a robust feature we provide as a part of our Premiere plan. If you don’t yet have a NodePing account, please sign up for our free, 15-day trial and try out our on-premises monitoring and see how our AGENT can help you with monitoring your VPN connections.
We’ve rolled out some UI and feature updates for NodePing today. We hope you find them helpful. I’ll summarize the changes here. Look here for future posts, which will go into more details for each.
Delayed Notifications:
Youcan now set a delay on ‘down’ alerts. This will help make your notifications more actionable for frequently flapping services. This new feature can also be used to escalate alerts or notify support/management if services remain offline. This feature has been available for a while in our API, but hasn’t been in our documentation, and has now been added to our UI as well. See the ‘Delay’ drop down in the Notification section of your check.
Check Cloning: You can now clone an existing check, with all its settings, in our UI to create a new check. This will help reduce “clickty-clickty” syndrome when setting up a lot of checks with similar settings. Click on the label of the check you want to clone to display the details to reveal the ‘Clone Check’ link on the far right.
Notification Dependencies:
When an edge router or server fails, it’s assumed that all the services that depend on them will also fail. It’s not helpful to receive hundreds of alerts for dependent services. You can now set another check as a notification dependency on each check. If the dependent check is already failing, notifications will be suppressed. Use this to avoid alert floods when bottleneck services fail. You can find the ‘Dependency’ drop down in the Notification section of each check.
Disable All Notifications:
There is now a link in the Contacts tab to “Disable notifications”. Use this to suppress all alerts until you re-enable them using the same link. It’s another way to help avoid the distraction of alert floods during big outages.
Disable Checks:
Now you can disable multiple checks with one click. You’ll find the “Disable All Checks” link in the Account Settings – General Settings tab. You can also apply filters based on label, target, or check type to, for example, disable all PING checks or all checks pointing to “example.com”. Use this to disable checks during planned outages/maintenance or to quiet down your logs when troubleshooting.
All the above new features, except check cloning, are also available via our API. If you have any questions about these new features, reach out to support@nodeping.com; we’re happy to help.
NodePing is happy to announce our newest notification method – twitter direct messages. The ability to receive a twitter direct message is a great addition to our current notification system that already includes unlimited email, international SMS, and voice calls.
Twitter notifications are in testing at this point. They are available on all accounts so please do kick the tires and let us know how things work for you at support@nodeping.com.
You’ll need to follow @NodePing in order to get direct message alerts. Then add your twitter handle in your contact record and in your check’s notification section and we’ll send you a private and discrete ‘direct message’ (not an embarrassing public tweet) when that check goes down and again when it comes back up.
Let us know in the comments how this new notification type is working for you and what you’d like to see added next – instant message (IM), HTTP POST to url, carrier pigeon, etc?
One of the features that we get asked about fairly often is public reports for monitoring results. It has been on our todo list from the start, and starting today they are available.
Of course, not every check on your list is something you want out in public. So this feature can be turned on individually for each check. Each check that you enable for public reports will have its own URL.
We’ve intentionally made these reports fairly plain, without much branding. This makes them suitable for framing or other methods you could use to embed them in your own site.
These reports will see further enhancements in the near future. As always your feedback is welcome.
This week we’ve launched pinghosts in two additional locations with automatic rechecking across locations. So if the New Jersey pinghost reports a monitored site is down, we now automatically recheck it from Texas and California before we send notifications.
How many times we do this depends on your “Sensitivity” setting for the check. The default setting of High rechecks once from each of the other two locations. These rechecks take a few seconds each, and the notification will be sent off in around 30 seconds. A setting of “Very Low” rechecks the service ten times, and with the extra rechecking the notification gets out in around 2 minutes. A setting of “Very High” doesn’t do a recheck at all, so if any check shows the service is not responding as expected we send the notice immediately.
This addition of the multi-site rechecks is one of the features we get asked about most often, and we’re very happy to get it rolled out to our production service. We’d love to hear from you about additional features that you’d like to see in our service.
Server monitoring is an essential part of any business environment that has services. Even if you don’t have your own servers and use cloud-based services, you’ll want to know about downtime. You don’t want to find out your web site is down from customers and you don’t want your boss to be the one to point out the email server has wandered off into the weeds. Done properly, server monitoring alerts those responsible for the services the minute they’re unavailable, allowing them to respond quickly, getting things back up and running.
David and I have been responsible for servers and server monitoring for years and have probably made nearly all the mistakes possible while trying to do it properly. So listen to the war stories from a couple of guys with scars and learn from our mistakes.
Here are 10 common server monitoring mistakes we’ve made.
1. Not checking all my servers
Yeah it seems like a no-brainer but when I have so many irons in the fire, it’s hard to remember to configure server monitoring for all of them. Some more commonly forgotten servers are:
Secondary DNS and MX servers. This ‘B’ squad of servers usually gets in the game when the primary servers are offline for maintenance or have failed. If I don’t keep my eye on them too, they may not be working when I need them the most.
New servers. Ah, the smell of fresh pizza boxes from Dell! After all the fun stuff (OS install, configuration, hardening, testing, etc) the two most forgotten ‘must-haves’ on a new server are the asset tag (anybody still use those?) and setting up server monitoring.
Temporary/Permanent servers. You know the ones I’m talking about. The ‘proof of concept’ development box that was thrown together from retired hardware that has suddenly been dubbed as ‘production’. It needs monitoring too.
2. Not checking all services on a host
We know most failures take the whole box down but if I don’t watch each service on a host, I could have a running website while FTP has flatlined.
The most common one I forget is to check both HTTP and HTTPS. Sure, it’s the same ‘service’ but the apache configuration is separate, the firewall rules are likely separate, and of course HTTPS needs a valid SSL certificate. I’ve gotten the embarrassing calls about the site being ‘down’ only to find out that the cert had expired. Oh, yeah… I was supposed to renew that, wasn’t I.
3. Not checking often enough
Users and bosses have very little tolerance for downtime. A lesson learned when trying to use a cheap monitoring service that only provided 10 minute check intervals. That’s up to 9.96 minutes of risk (pretty good math, huh?) that my server might be down before I’m alerted. Configure 1 minute check intervals on all services. Even if I don’t need to respond to them right away (a development box that goes down in the middle of the night), I’ll know ‘when’ it went down to within 60 seconds which could be helpful information when slogging through the logs for root cause analysis later.
4. Not checking HTTP content
Standard HTTP check is good… but the ‘default’, ‘under-construction’ Apache server page has given me that happy 200 response code and a green ‘PASS’ in my monitoring service just like my real site should. Choose something in the footer of the page that doesn’t change and do an HTTP content matching check on that. Don’t use the domain name though – that may show up in the ‘default’ page too and make that check less useful.
5. Not setting the correct timeout
Timeouts for a service are very subjective and should be configurable on your monitoring service. Web guys tell me our public website should load under 2 seconds or our visitors will go elsewhere. If my HTTP service check is taking 3.5 seconds, that should be considered a FAIL result and someone should be notified. Likewise, if I had a 4 second ‘helo’ delay configured in my sendmail, I’d want to move that timeout above that.
Timeouts set to high let my performance issues go unnoticed; timeouts set too low just increase my notification noise. It takes time to tweak these on a per-service level.
6. Not realizing external and internal monitoring are different
When having an external monitoring service watch servers behind my firewalls, I may need to punch some holes in said firewall for that monitoring to work properly. This can be a real challenge sometimes as many monitoring services use multiple locations and then dynamically pick one to monitor my servers making it hard to maintain a white-list of their IPs or hostnames to let in my network.
Another gotcha I’ve run into is resolution of internal and external DNS views. If these aren’t configured properly, you’ll most likely get lots of ‘down’ notifications for hosts that are simply unreachable.
7. Sensitivity too low/high
Some servers or services seem more prone to having little hiccups that don’t take the server down but may intermittently cause checks to fail due to traffic or routing or maybe the phase of the moon. Nothing’s more annoying than a 3AM ‘down’ SMS for a host that really isn’t down. Some folks call this a false positive or flapping- I call it a nuisance. Of course I should jump every time a single ping looses its way around the interwebs and every SMTP helo goes unanswered – but reality sets in and a more dangerous condition might occur – I may be tempted to start ignoring notifications because of all the false positives.
A good monitoring service handles this nicely by allowing me to adjust the sensitivity of each check. Set this too low and my notifications for legitimate down events take too long to reach me but set it too high and I’m swamped with useless false positive notifications. Again, this is something that should be configured per service and will take time to tweak.
8. Notifying the wrong person
Nothing ruins a vacation like a ‘host down’ notification. Sure, I’ve got backup sysadmins that are covering it but I forgot to change the service so notifications get delivered to them and not me.
Another thing I’ve forgotten to take into consideration is notification time windows. John’s always the first in the office at 6AM, he should get the alerts until Billy shows up at 9AM because we all know Billy is useless until he’s had that first hit of coffee.
9. Not choosing the correct notification type
Quick on the heels of #8 is knowing which type of notification to send. Yeah, I’ve made the mistake of configuring it to send email alerts when the email server is down. Critical server notifications should almost always send via SMS.
10. Not whitelisting the notification system’s email address
Quick on the heels of #9 (we’ve got lots of heels around here) is recognizing that if I don’t whitelist the monitoring service’s email address – it may end up in the bit bucket. Mental note – dang, all out of mental note paper.
Bonus!
11. Paying too much
I’ve paid hundreds of dollars a month for a mediocre monitoring service for a couple dozen servers before. That’s just stupid. NodePing costs $10 a month for 1000 servers/services at 1 minute intervals and we’re not the only cost effective monitoring service out there. Be sure to shop around to find one that fits your needs well. Know that most services are charging way too much though.
They say a wise man learns from his mistakes but a wiser man learns from the mistakes of the wise man. Nuff said, true believer.
I know this letter won’t come as much of a surprise to you. We’ve been growing apart for a while now but today we officially part ways.
It wasn’t easy to write this. You and I have a lot of history. Hard to believe it was over 10 years ago when you welcomed me into your arms. You were young, sexy, and a breath of fresh air compared to my ex, Perl (shudder – lets not go there). It didn’t take long for our relationship to start paying the bills. In fact, every job I’ve had in the last decade had you on a pedestal.
We had plenty of good times. Remember how we survived a front-page CNN link and pulled in $500k in 14 days? And all the dynamic PDF creation over the years still brings a smile on my face.
But we had our rough times too. I could go the rest of my life without ever hearing the words ‘register globals‘ again. And you know quite well that I still bear the scars from creating SOAP clients with you. While neither of us has been truly faithful (what ever happened to V6 and UTF-8?), we’ve always been able to work out our differences up to now.
But starting tomorrow, for the first time in 10 years, my ‘day job’ won’t include you. I’m leaving you for node.js. We were introduced by our mutual friend, JQuery. At first I thought she was just the latest flavor of the month; popular among the guys on the mailing lists but now I’ve fallen victim to her async charm and really think we have a future together.
When you and I started having fun on the couch a year ago, I thought maybe our relationship would just keep going. But then node and I spent some time on that couch and – oh, what she can do with JSON makes my toes curl. To be perfectly honest, you just can’t compete with her. She’s all that you used to be – young, sexy, and fast. I’m sure some of your other boyfriends will probably argue with me about it but I’ve been smitten. While they’re fighting with you over namespacing, she and I will be branching in non-blocking ways and spawning like crazy.
I’m not saying we’ll never see each other again – heck, you’re even serving this blog. But I’m moving on and I hope you will too. If you want to see what node.js and I are up to, stop by some time. Maybe we can even help you keep an eye on all those fatal exceptions of yours.
Some time ago Shawn and I were lamenting about what a pain network and service monitoring can be. There are some very good open source applications out there for doing this sort of thing. We’ve both used several versions of Nagios, and it works really well. If you need to run your own monitoring or write your own custom plugins (which we’ve done in the past), that’s a good option. If what you want is to monitor a bunch of services easily without having to put up and maintain another server just for that, a service that does it for you is more attractive.
There are a number of services out there that do pings, HTTP checks and a variety of other checks with notification. Some of them even start out at low cost or free, but if you have more than a handful of hosts and ports to monitor, they get pricey fast, or they don’t let you check very often, or they have some other catch that makes them just not do what you want. Some of them you need a special graduate degree from MIT to understand the pricing.
So we were trying to figure out how to get monitoring done reliably and cost effectively for a set of services we were responsible for at the time, and saying to each other “Someone should create a service that is easy, just does what you need it to do reliably, and doesn’t cost a lot.” Someone, as it turns out, was us.
More recently Shawn and I were once again chatting about the kinds of things geeks talk about, and one of those things was Node.js. I had been working on a few projects just as a proof of concept. It was clear that Node.js has some real strengths for writing scalable asynchronous services. In the course of the conversation, it occurred to us that we could create a service that would scale to many thousands of checks with very low incremental cost. If someone wanted to check thirty or fifty hosts every minute, the cost would be very similar to checking three sites every fifteen minutes. NodePing was born.
The name NodePing stuck with us, not because it uses Node.js (although it does, and we’re proud of that fact), but because “node” refers generically to something on the network. Of course, it’s much wider than that, and the most common checks don’t turn out to be pings. We think the name NodePing conveys “checks on things on the ‘net” well, even beyond pinging nodes. Our goal is to let you check what you want, when you want, for not much money.
As we wrap up our initial testing (with thanks to our beta testers for some great feedback) and move towards taking on customers in real quantity, I recognize that getting here has been quite a process from that first conversation about how lousy the options were for monitoring. I wish this service had been available when I was responsible for a range of web and email services years ago. It would have made life easier, for a great value at the price. We hope you see it that way too.
What do you want from a monitoring service? We are creating the service we wished we’d have had. What would you add? Is there something you’ve been frustrated about monitoring services, and just wish someone would fix already? Let us know!
NodePing is an Internet web site and server monitoring service at an amazing price, allowing you to check all your website and servers as frequently as every minute, for as little as $10 a month. Our low prices include unlimited international SMS, slack, and email notifications. The 'Premiere' plan also includes unlimited voice notifications.