Starlink Monitoring with NodePing
2025/07/15 Leave a comment
With a Starlink antenna on hand, we thought it would be a fun experiment to see what the results would be of monitoring a Starlink connection from a residential connection with our AGENT check type. The AGENT check can be used to monitor any outbound connectivity from your location on any network. Starlink was an interesting case study for us to try our AGENT monitoring from. Some information we wanted to see was:
- ICMP reliability
- Packet loss out to the internet
- HTTP connections
- DNS queries
We targeted a handful of popular services, including our own blog page as well as a website that is hosted in Seattle. We targeted these DNS providers:
- Google DNS
- Quad9
- Cloudflare
- OpenDNS
For popular websites, we targeted:
- google.com
- Our blog (WordPress)
- An employee blog site in Seattle
These were all tested over IPv4 and IPv6, each website had its DNS record monitored over the different DNS providers, as well as HTTP monitoring directly to an IP address for that site to rule out DNS issues.
Hardware
To connect to Starlink’s network, the standard antenna was used. The computer was a Raspberry Pi 4 running Raspberry Pi OS.
ICMP Monitoring
The route that was taken from my current location was through Starlink’s network and then back down through Seattle and then out to the rest of the Internet. Below is an MTR from the home network to blog.nodeping.com on WordPress:
Start: 2025-06-05T17:10:24+0100
HOST: raspberrypi Loss% Snt Drop Rcv Last Best Avg Wrst Jttr Javg Jmax Jint
1.|-- 192.168.1.1 90.0% 10 9 1 1.0 1.0 1.0 1.0 0.0 0.0 0.0 0.0
2.|-- 100.64.0.1 30.0% 10 3 7 17.6 17.6 65.5 298.4 5.0 81.7 275. 516.6
3.|-- 172.16.252.130 40.0% 10 4 6 19.1 19.1 49.6 154.4 5.3 44.0 130. 239.1
4.|-- 206.224.65.146 40.0% 10 4 6 1192. 654.2 1011. 1192. 55.2 106. 405. 537.7
5.|-- 206.224.64.37 30.0% 10 3 7 20.5 20.5 30.4 43.6 9.9 10.1 17.5 59.4
6.|-- 206.81.81.70 40.0% 10 4 6 26.2 19.9 30.2 39.6 13.4 6.0 18.1 32.3
7.|-- 192.0.78.12 50.0% 10 5 5 27.2 25.0 27.1 29.9 0.6 1.6 4.9 7.2
Each hop is as follows:
- Router
- SpaceX CGNAT
- SpaceX internal IP
- SpaceX public IP
- SpaceX public IP
- Seattle Internet Exchange
- automattic
We assigned both PING and MTR checks to our NodePing AGENT. One to have a simple ping to check uptime, and the MTR to monitor packet loss and other networking statistics.
PING Monitors
After a month of monitoring, the results showed that my average ping uptime was roughly around 99.6% for IPv6 and 99.8% for IPv4

The majority of incidents were 1 minute timeouts. Only a few longer outages occurred. A few outages are noteworthy:
- A 10 minute outage while the antenna was moved out of the way and obstructed
- A 36 minute outage that was consistent with full network downtime shown by the other results
- A 7 minute outage that also consistently happened with other checks
The average day showed about 10-20 events when there was typically a 1 minute timeout. This is roughly a 7-day sample of pinging Google’s site:
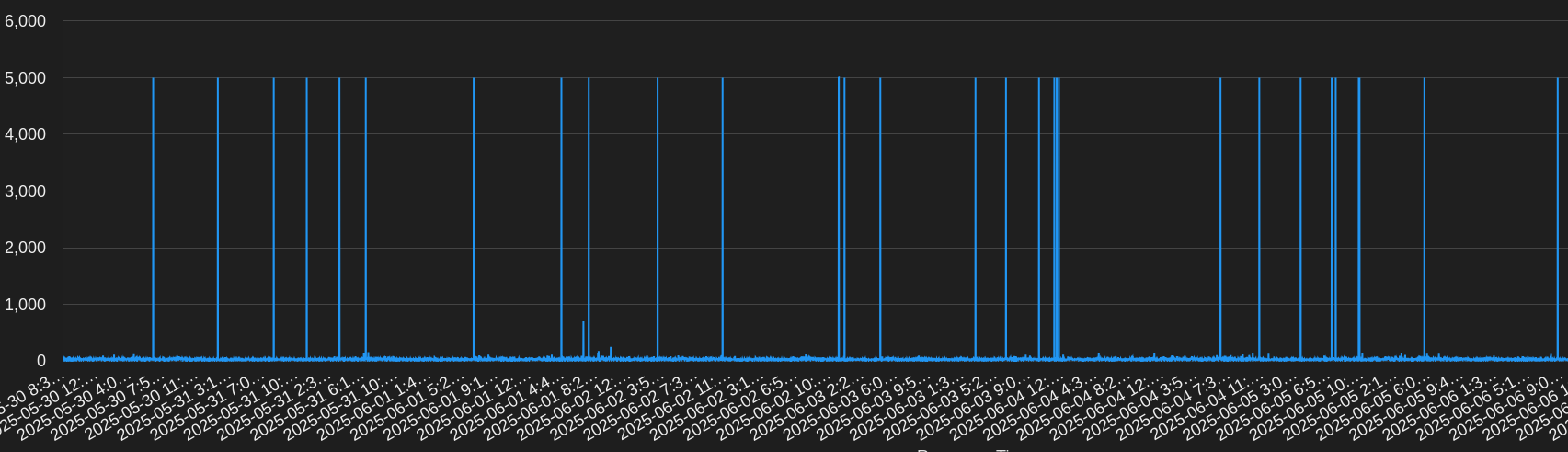
Generally, response times were very good and in the 20-30ms range with some blips up to about 100ms.
MTR Monitors
Our MTR monitoring paints a somewhat similar picture. The average uptime was about 99.7% to 99.9%. This is running an MTR count of 10 and expecting packet loss to be below 5%. Some observations:
- A time when Google IPv6 had high packet loss for 9 minutes, at the same time OpenDNS was unreachable for 7 minutes
- Moving the antenna was detected just like with the PING checks. This resulted in roughly 10% to 50% packet loss incidents
- Like PING, there were quite a few times running an MTR would show packet loss or an unreachable target for a minute
- I noticed most of my checks had packet loss more often in the evenings
- At one point Google and Facebook had high packet loss or were unreachable for about 40 minutes
Below are some results from the MTR check to Facebook over IPv6:


I noticed that inter arrival jitter was high. The average seemed to be roughly in the 30s, however, it would also frequently go up into the upper 100s. This could potentially impact RTP streams.
Other Monitoring
DNS Monitors
During my testing, DNS checks were rather boring. The overall uptime was 99.9% with minimal timeouts or other issues. One day OpenDNS, Cloudflare, and Google DNS had 3 to 5 minutes of timeouts, but at different times of the day. Some days Quad9 ended up doing worse than others, but overall all the DNS services had that 99.9% uptime. At some times some services would timeout at the same time, but not others. Average responses were around 30-60ms. There were some incidents that happened, but I will expound on those in the next section.
Earlier it was noted that the antenna was moved and obstructed for a little while. All the checks were impacted by this obstruction. However, DNS was not.
HTTP Monitors
Last of all, HTTP monitors. The average uptime was 99.8%. While monitoring HTTP, I was able to use information from my DNS checks to get additional insights into the failures. While an HTTP check will mention it cannot resolve a hostname, the DNS checks provided additional detail into DNS failures and helped me to identify the cause of failed HTTP connections. For example, one day there was about a 5 minute window of failures when some hosts were unable to resolve hostname and others were getting ENETUNREACH errors. My default DNS resolver was Google DNS. At that time, I noticed that the other DNS services were not failing, only Google DNS. With that information, I was able to determine that I was unable to reach my websites because of the DNS provider I was using.
For some of my HTTP checks, I set some of the targets to be the IP address only so DNS was not resolved. At times when failures happened, I could see if the DNS and no DNS checks were failing. If they were, the site was unreachable. If only the DNS checks were failing, then the issue was likely with DNS. There was one outage that was 36 minutes long where my DNS and no DNS checks were failing.

The TLS EACCES errors show that a secure TLS connection could not be established. This often happens when there is a networking issue, since I know that the TLS certificates on the end are correct. This is especially obvious here since the TLS connection failures are happening to multiple services.
Conclusion
After a month of monitoring, it is clear to see that there is some network instability with Starlink. The service could not quite reach three 9s outbound. This could be perfectly sufficient for some, however, mission critical services will likely have frequent reachability issues.
Using AGENTs to monitor my Starlink connection provided me with some interesting results. While using our public probes, there were no incidents with the services I monitored. Using an AGENT to monitor outbound connections to services provided useful data to determine connectivity issues to commonly used services. This is useful when you need to monitor for incidents from a Starlink or any other remote connection and respond to them.
If you have any remote POPs that you need to monitor, try out our NodePing AGENTs today. We offer a free, no-obligation 15-day trial. The best way to see if NodePing meets your needs is to try it out.
